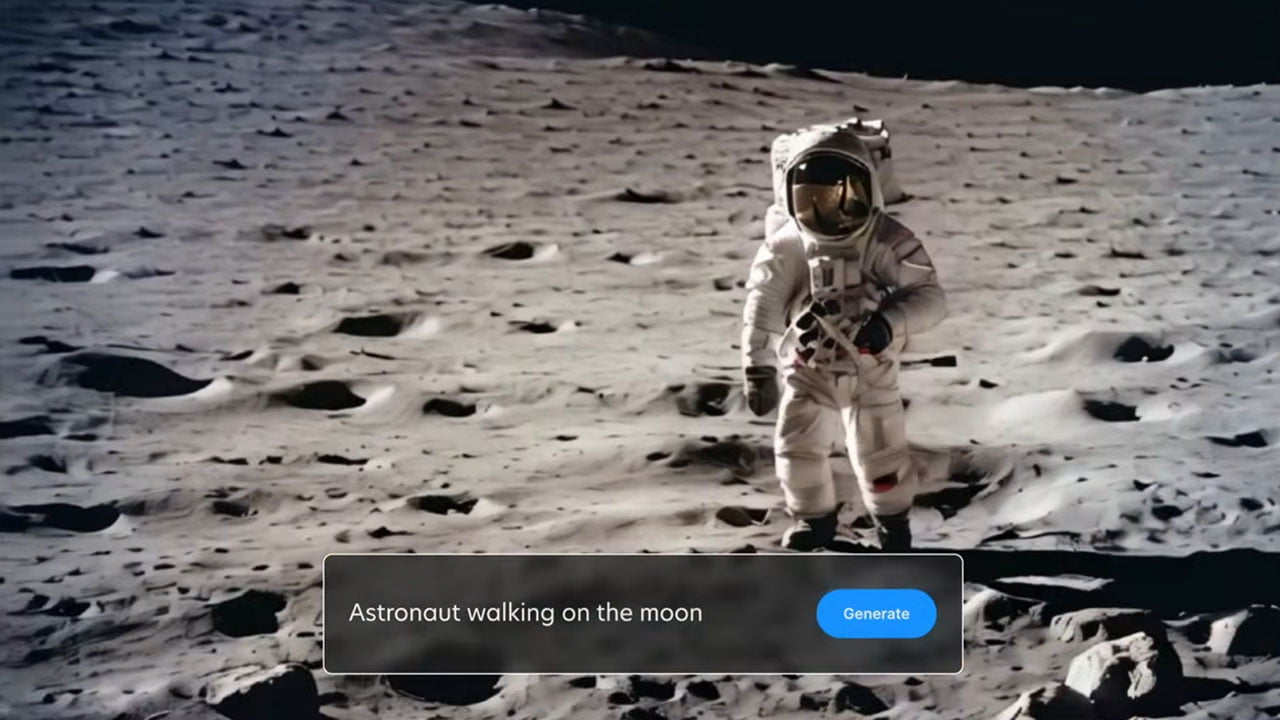
Stability AI, la compañía detrás del modelo de inteligencia artificial conocido como «Stable Diffusion», ha dado un paso adelante en el campo de la generación de contenido audiovisual con el lanzamiento de «Stable Video Diffusion». Esta nueva herramienta permite la creación de videos a partir de imágenes estáticas, utilizando tecnologías avanzadas de inteligencia artificial.
Stable Video Diffusion se presenta en dos modelos de imagen a video, cada uno capaz de generar secuencias de 14 a 25 fotogramas de duración. Estos modelos operan a velocidades de entre 3 y 30 fotogramas por segundo y ofrecen una resolución de 576 × 1024. La herramienta es capaz de realizar síntesis multivista a partir de un solo cuadro, lo que demuestra su capacidad para ajustarse a diferentes conjuntos de datos multivista.
Limitaciones de Stable Video Diffusion
A pesar de los avances que representa, Stable Video Diffusion enfrenta ciertas limitaciones. Los videos generados son relativamente cortos, con una duración de menos de 4 segundos, y carecen de un fotorealismo completo. Además, el sistema no permite movimientos de cámara complejos, limitándose a paneos lentos, y no tiene capacidad para controlar o generar texto legible. Otro desafío es la generación precisa de personas y rostros.
El desarrollo de Stable Video Diffusion subraya la importancia del video en el campo de la inteligencia artificial generativa. Aunque actualmente está disponible sólo para fines de investigación, su potencial para aplicaciones en sectores como la publicidad, la educación y el entretenimiento es notable. Sin embargo, también plantea preocupaciones sobre posibles abusos, como la creación de deepfakes y violaciones de derechos de autor.