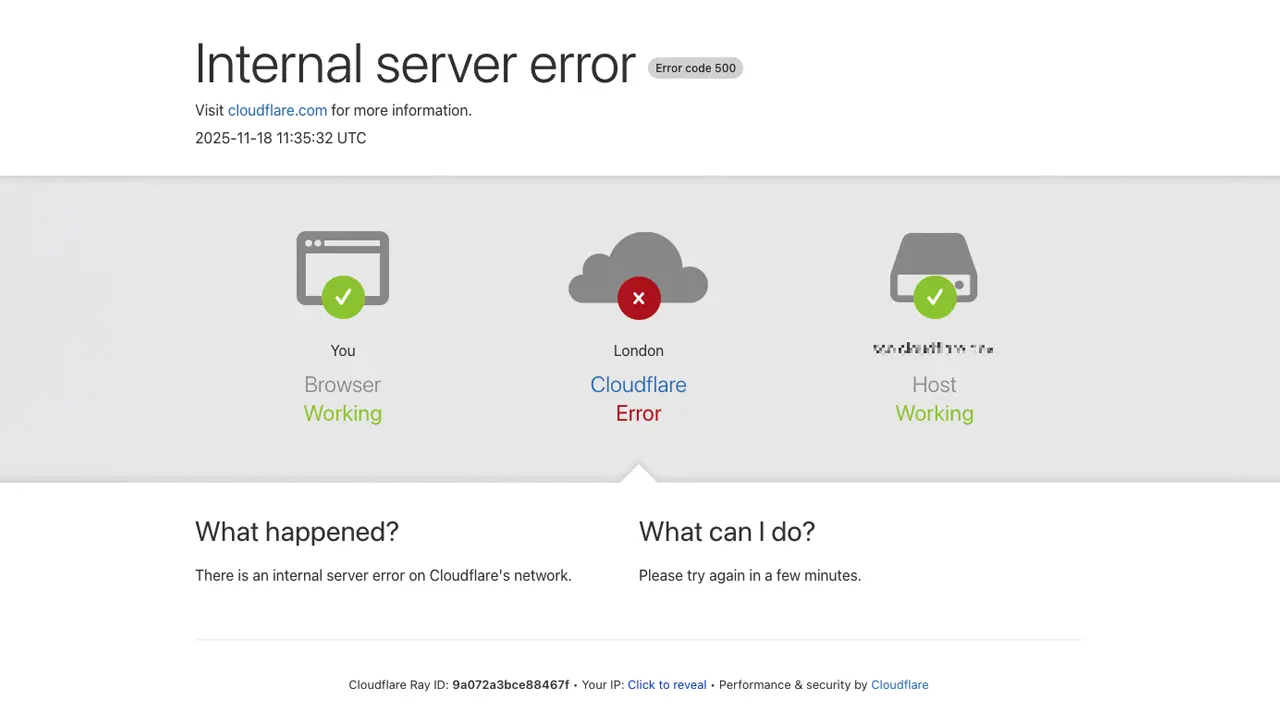
Un fallo interno en Cloudflare dejó sin acceso a una amplia parte de Internet durante ayer, martes 18 de noviembre, afectando a servicios globales como ChatGPT, X (Twitter), Spotify, YouTube y Uber. El incidente, que comenzó a las 11:20 UTC, interrumpió el tráfico en gran parte de la red durante casi seis horas y provocó que millones de usuarios se encontraran con mensajes de error al intentar acceder a sitios dependientes de la infraestructura de la compañía.
Durante los primeros minutos del suceso, la empresa sospechó que estaba siendo víctima de un ciberataque masivo. Sin embargo, tras una investigación interna, determinó (oficialmente) que la caída se originó por un error en su propio sistema de gestión de bots, responsable de filtrar el tráfico automatizado y proteger a sus clientes frente a ataques DDoS y otras amenazas.
La falla en el sistema de bots de Cloudflare
El problema surgió cuando un cambio en los permisos de una base de datos provocó la generación de un «feature file», archivo usado por el módulo de gestión de bots, con entradas duplicadas. Ese archivo, que se actualiza cada cinco minutos en todos los servidores de la red, duplicó su tamaño y superó el límite aceptado por el software encargado de distribuir el tráfico, lo que desencadenó una reacción en cadena de errores.
Cada vez que el archivo se actualizaba, algunas máquinas recibían una versión defectuosa, haciendo que el sistema cayera y se restableciera de forma intermitente. Esa secuencia de fallos cíclicos llevó a los ingenieros a pensar inicialmente en un ataque distribuido de denegación de servicio (DDoS), ya que la red parecía colapsar y recuperarse de manera rítmica.
El patrón coincidió con otro incidente fortuito: la página de estado de Cloudflare, que opera fuera de su infraestructura principal, también dejó de funcionar temporalmente, lo que reforzó la sospecha de un ataque externo. Más tarde se comprobó que ambos eventos eran independientes.
Restauración y medidas futuras
A las 14:30 UTC, los equipos de ingeniería lograron detener la propagación del archivo corrupto y restauraron una versión anterior, lo que permitió reanudar la circulación normal del tráfico. Según los registros oficiales, todas las operaciones volvieron a la normalidad a las 17:06 UTC.
El corte afectó a los servicios de entrega de contenido (CDN) y también a herramientas internas como Cloudflare Access, Workers KV, Turnstile y la consola de administración de clientes, donde miles de usuarios no pudieron iniciar sesión durante horas.
El director ejecutivo de la compañía, Matthew Prince, calificó el suceso como «el peor desde 2019» y ofreció disculpas públicas: «sabemos que defraudamos a Internet hoy». Cloudflare adelantó que implementará nuevos mecanismos de seguridad y control de archivos para evitar que errores similares puedan volver a propagarse por toda su red global.